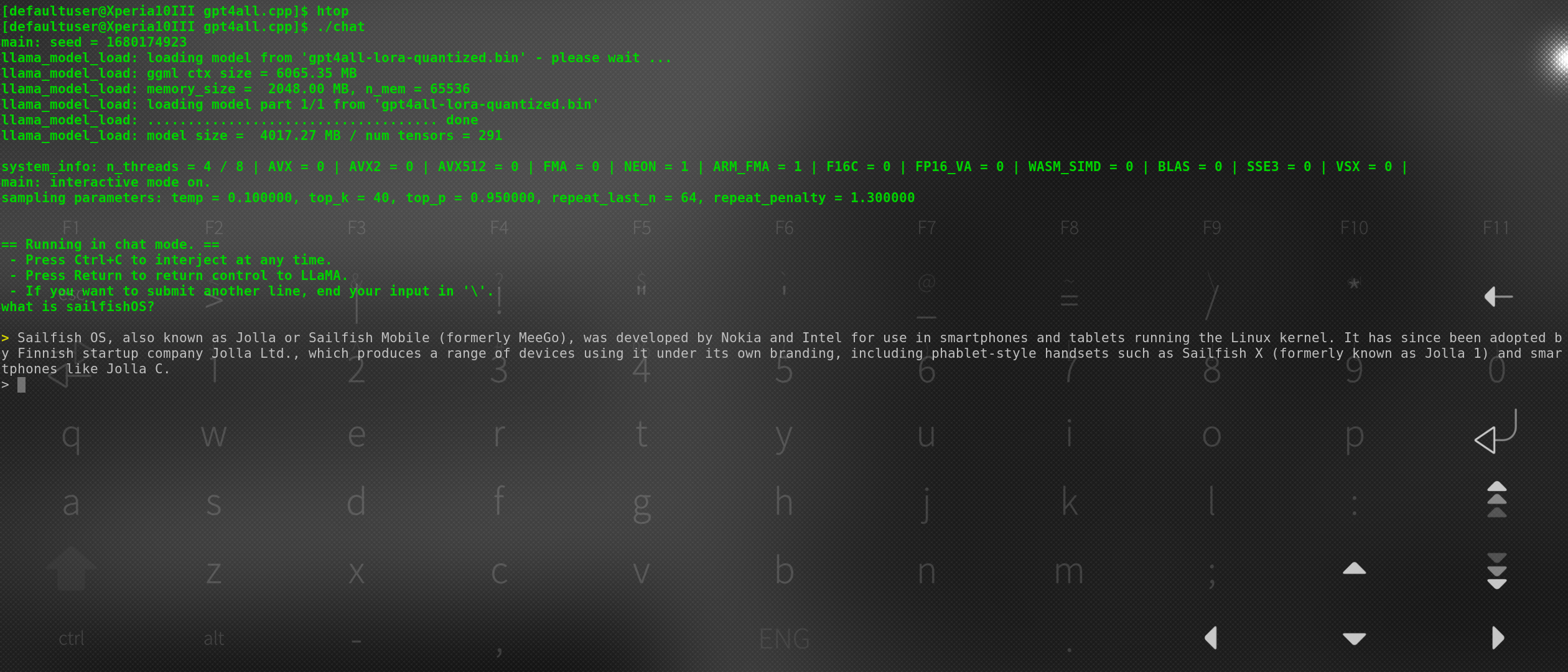
Speed isn’t great, parsing input took 40sec, reply around 3 minutes, but it works.
git clone https://github.com/zanussbaum/gpt4all.cpp
cd gpt4all.cpp/
make chat
wget https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin
Model is 4GB and had to increase swap (overshot it by a lot making 4G extra, in the end it needed only 400Mb extra it seems, as it ended up using 1.35G of swap)
How to increase swap: Low memory, apps crashing - change zram settings or add swapfile? [4.x] - #22 by Schrdlu
7 Likes
Pardon my ignorance, why did you have to increase swap? Was it to compile and get the model, or was it to run the chat command?
To run/load the model, it’s supposed to run pretty well on 8gb mac laptops (there’s a non-sped up animation on github showing how it works). Alternatively to run on gpu they say you need 16gb vram (then again that might’ve been different one, this one incorporates cpp version of llama 7b finetuned with lora and a chat interface (probably missed a couple of buzzwords as I’m not following that whole hypetrain too closely was just curious if it would run at all as whisper is close to being usable on device without apis/phone number registration etc))
Out of curiosity, why not LLAMA ? I think they’re less resource intensive?
This is llama 7b quantized and using that guy’s who rewrote it into cpp from python ggml format which makes it use only 6Gb ram instead of 14
edit: from github:
This combines the LLaMA foundation model with an open reproduction of Stanford Alpaca a fine-tuning of the base model to obey instructions (akin to the RLHF used to train ChatGPT) and a set of modifications to llama.cpp to add a chat interface.
EDIT2: however I remember someone pointing out in one issue in llama.cpp that on some arm based device python llama was running faster than the cpp, so might be worth a try, but 10Gb of swap will probably ruin it
edit3: this is supposed to be how it runs on a laptop, seems pretty usable already, maybe on Xperia V or VI
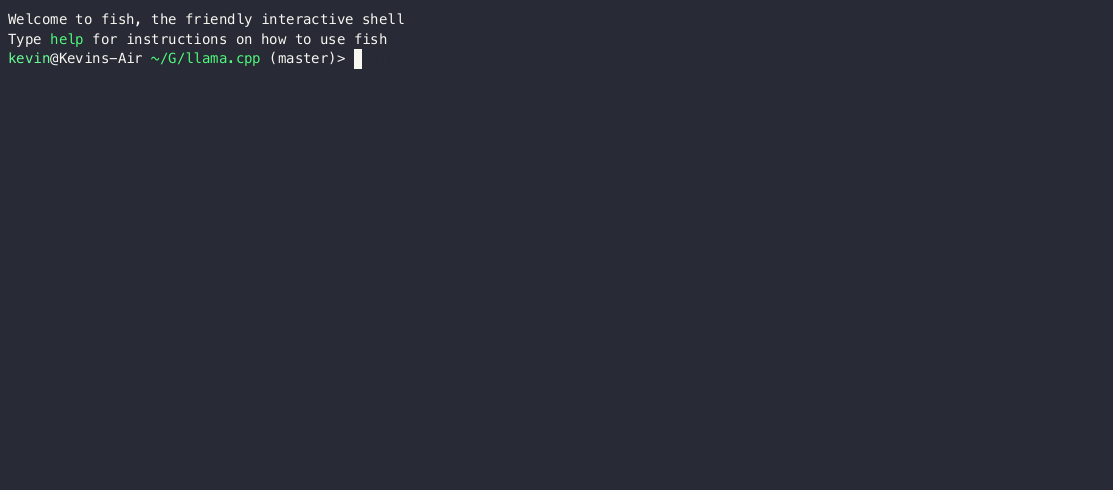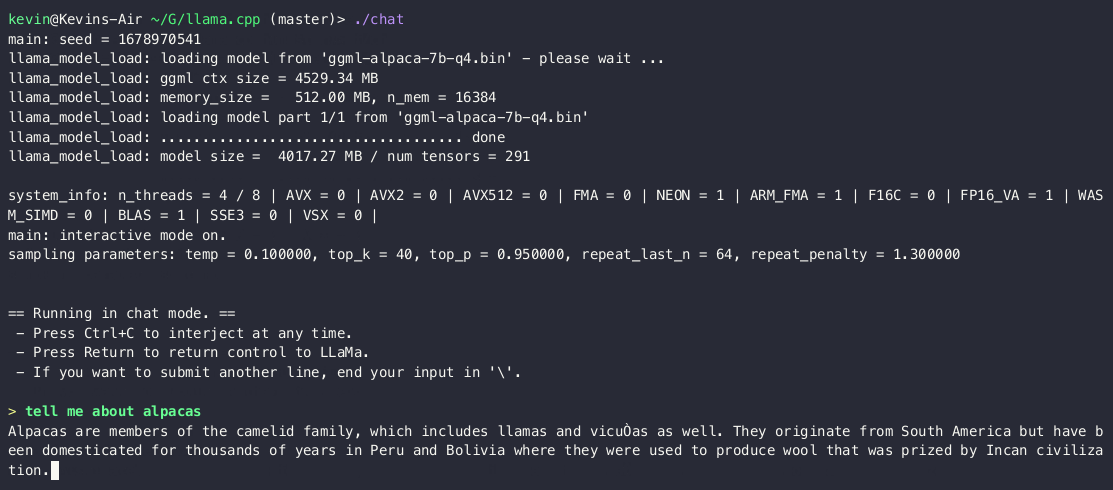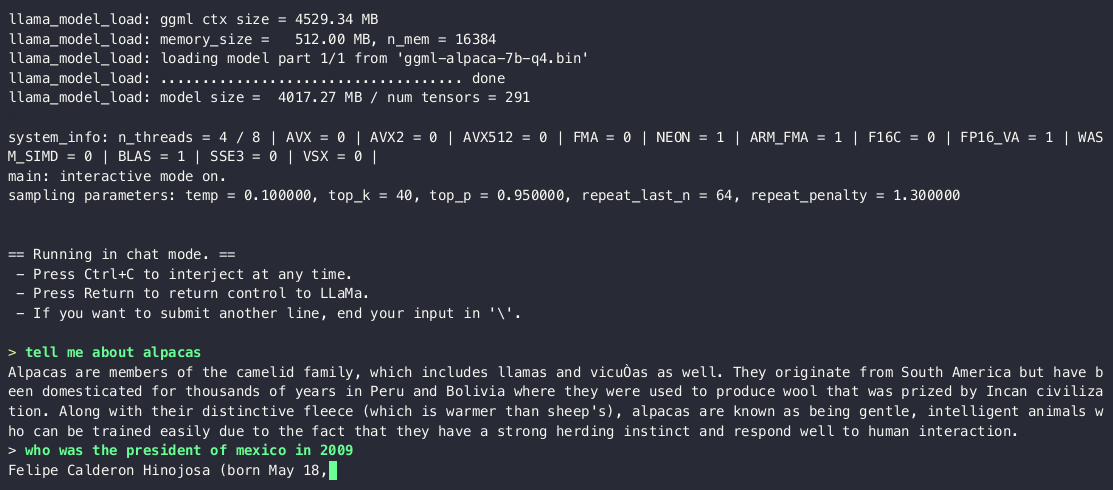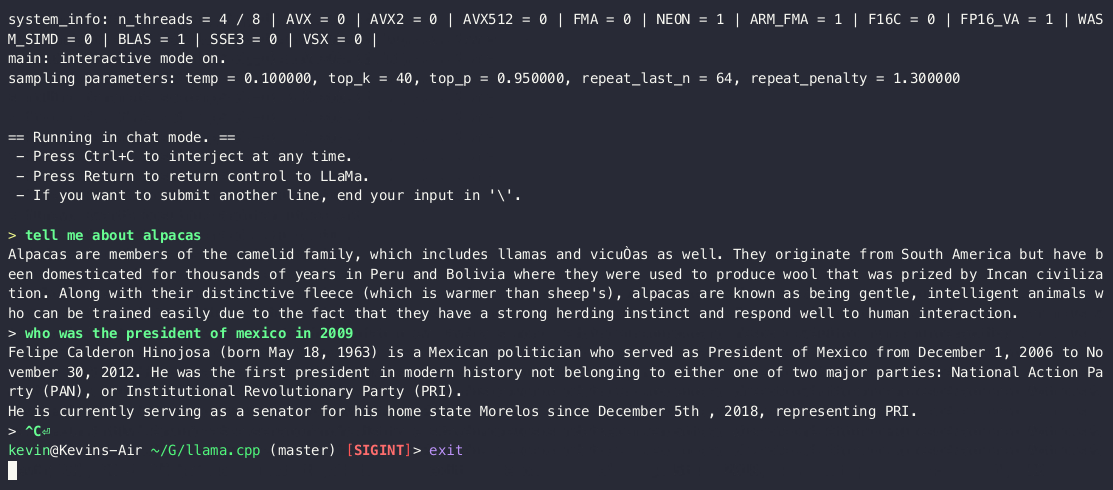
Ah, sheesh! Thanks! That’s. Exactly. What. I. Was. Looking. For. But it’ll take me months to get to it. I’m composing music in supercollider and trying to design an api while hunting for bugs that no language model has yet to classify.
2 Likes
The python c bindings are not bad  scipy is pretty dope.
scipy is pretty dope.